Welcome to Andy's Blog!
一念净心,花开遍世界-
Spring-IoC
Spring
Spring是一个容器,管理着整个应用程序中所有的bean的生命周期和依赖关系。这个框架主要用于降低耦合度,对于主业务逻辑之间的采用的是IoC,对于系统业务逻辑与主业务逻辑之间采用的是AOP,是一个分层的一站式轻量级开源框架。
图里面每个最小级别方块对应一个jar包。IoC
控制反转(IOC,Inversion of Control),是一个概念,是一种思想。指将传统上由程序代码直接操控的对象调用权交给容器,通过容器来实现对象的装配和管理。控制反转就是对对象控制权的转移,从程序代码本身反转到了外部容器。
IoC是一个概念,是一种思想,其实现方式多种多样。当前比较流行的实现方式有两种:依赖注入和依赖查找。依赖注入方式应用更为广泛。
依赖查找:Dependency Lookup,DL,容器提供回调接口和上下文环境给组件,程序代码则需要提供具体的查找方式。比较典型的是依赖于JNDI系统的查找。 依赖注入:Dependency Injection,DI,程序代码不做定位查询,这些工作由容器自行完成。
依赖注入DI是指程序运行过程中,若需要调用另一个对象协助时,无须在代码中创建被调用者,而是依赖于外部容器,由外部容器创建后传递给程序。
Spring的依赖注入对调用者与被调用者几乎没有任何要求,完全支持POJO之间依赖关系的管理。
依赖注入是目前最优秀的解耦方式。依赖注入让Spring的Bean之间以配置文件的方式组织在一起,而不是以硬编码的方式耦合在一起的。
IoC程序举例
- 定义接口与实现类 ```java public interface ISomeService { void doSome(); }
public class SomeServiceImp implements ISomeService {
@Override public void doSome() { System.out.println("do some"); } } ```-
创建Spring配置文件
applicationContext.xml文件约束在%SPRING_HOME%\docs\spring-framework-reference\html\xsd-configuration.html文件中。 -
定义
<bean>标签 -
定义测试类
public class MyTest { @Test public void test01() { ISomeService service = new SomeServiceImp(); service.doSome(); } @Test public void test2() { // 创建容器对象 在类src下找 ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml"); // 从容器中获取对象 ISomeService service = (ISomeService) ac.getBean("myService"); service.doSome(); } @Test public void test3() { // 创建容器对象 在文件系统中找 ApplicationContext ac = new FileSystemXmlApplicationContext("D:/applicationContext.xml"); // 从容器中获取对象 ISomeService service = (ISomeService) ac.getBean("myService"); service.doSome(); } @Test public void test4() { BeanFactory factory = new XmlBeanFactory(new ClassPathResource("applicationContext.xml")); BeanFactory factory2 = new XmlBeanFactory(new FileSystemResource("applicationContext.xml")); ISomeService service = (ISomeService) factory.getBean("myService"); service.doSome(); } }
注意ApplicationContext与BeanFactory的区别:创建bean的时机不同。
- ApplicationContext容器,会在容器对象初始化时,将其中的所有对象一次性全部装配好。以后代码中若要使用到这些对象,只需从内存中直接获取即可。执行效率较高。但占用内存。 缺点:占用系统资源 优点:响应速度快
- BeanFactory容器,对容器中对象的装配与加载采用延迟加载策略,即在第一次调用getBean()时,才真正装配该对象。 缺点:相对响应速度慢 优点:不多占用系统资源
-
JavaWeb-Servlet3.0异步
Servlet3.0异步
这里的异步处理,是指服务端的异步处理,与AJAX是没有关系的。AJAX 是客户端的异步处理。
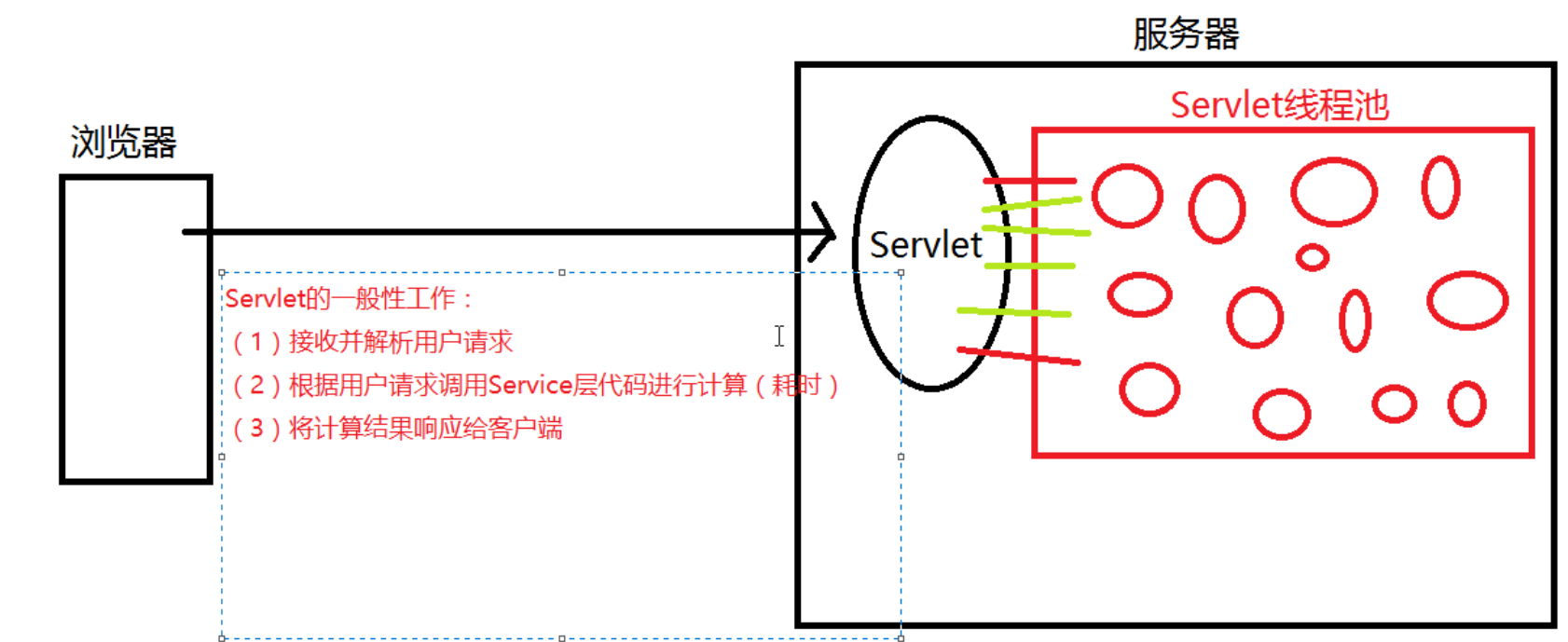 Servlet 是单例多线程的。当一个请求到达服务器后,服务器会马上为该请求创建一个相应的 Servlet 线程,为该请求服务。那么,一个请求就一定会有一个Servlet线程为之服务吗?答案是否定的。服务器会为每一个Servlet实例创建一个Servlet线程池,而线程池中该Servlet实例的线程对象并不是“取之不尽”的,而是有上限的。当达到该上限后,再有请求要访问该Servlet,那么该请求就只能等待了。只有当又有了空闲的Servlet线程对象后才能为该请求分配 Servlet 线程对象。
Servlet 是单例多线程的。当一个请求到达服务器后,服务器会马上为该请求创建一个相应的 Servlet 线程,为该请求服务。那么,一个请求就一定会有一个Servlet线程为之服务吗?答案是否定的。服务器会为每一个Servlet实例创建一个Servlet线程池,而线程池中该Servlet实例的线程对象并不是“取之不尽”的,而是有上限的。当达到该上限后,再有请求要访问该Servlet,那么该请求就只能等待了。只有当又有了空闲的Servlet线程对象后才能为该请求分配 Servlet 线程对象。对于Servlet 来说,其最典型的工作一般分为三步:
- 接收请求提交参数
- 根据提交参数调用Servic层代码对参数进行运算
- 接收到Service层的运算结果后,将结果响应给客户端
其中第二步有可能是一个耗时运算。在 Service 层代码对参数进行运算过程中,Servlet处于阻塞状态,等待着运算结果。如果在Service层代码运算过程中,将Servlet线程释放回Servlet线程池,当 Service运算结果出来后,再给出用户响应,这样 Servlet 线程就不会被长时间占用了。而Servlet3.0 的异步处理,即使用
异步Servlet与异步子线程所完成的异步处理,解决的就是这个问题所以每一个请求最好不要长时间占有Servlet线程。一个被占用的Servlet线程对象,什么时候会被释放呢?当服务器给出客户端响应后马上就会释放与该请求相关联的Servlet线程,即将Servlet线程放回到Servlet 线程池,然后,销毁请求request与响应response对象。所以对于耗时的操作,我们可以使用异步Servlet,让该Servlet只负责启动这个耗时运算线程即可。该Servlet完成启动任务后即可被释放,即该请求不再占用 Servlet线程。
Servlet 异步的实现
从 Servlet3.0开始,Servlet可以进行异步处理。所谓Servlet的异步处理,是指当一个具有耗时算的请求到达服务器后,Servlet仍会创建子线程去完成耗时运算,但Servlet不会等待子线程运算完毕后,再将该 Servlet线程释放,而是仅仅让当前 Servlet 完成对子线程的启动任务后直接释放,返回到Servlet线程池,让其它请求来使用。
- 定义异步线程
public class ComputerThread implements Runnable{ private AsyncContext async; public ComputerThread(AsyncContext async) { super(); this.async = async; } int sum = 0; @Override public void run() { try { PrintWriter writer = async.getResponse().getWriter(); writer.println("subthread start<br>"); for(int i=0; i<10; i++) { System.out.println(i); sum = sum + i; Thread.sleep(1000); } writer.print(sum + "<br>"); writer.println("subthread end<br>"); // 通知主线程执行完毕 底层执行销毁异步线程 async.complete(); } catch (InterruptedException | IOException e) { e.printStackTrace(); } } } - 定义异步Servlet
@WebServlet(value="/some", asyncSupported=true) public class SomeServlet extends HttpServlet { private static final long serialVersionUID = 1L; protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setContentType("text/html;charset=UTF-8"); PrintWriter writer = response.getWriter(); writer.println("main thread start <br>"); // 获取异步上下文对象 AsyncContext startAsync = request.startAsync(); // 开启异步线程 startAsync.start(new ComputerThread(startAsync)); writer.print("main thread end <br>"); } }运行结果
main thread start main thread end subthread start 45 subthread end
仔细查看运行结果可以看出,Servlet主线程的执行与子线程的执行是异步完成的,而非同步完成:先输出的是 Servlet 主线程中的所有数据,说明 Servlet 主线程是直接运行结束的。
异步应用举例
Servlet的异步处理的应用,一般是将异步子线程的处理结果存放到
Session域或ServletContext域中,让用户通过访问另一个指定页面来查看运算结果。 Servlet 的异步处理的最典型应用是:用户在某站点注册完毕后,需要到自己的邮箱中点击确认链接。下面的例子就是模拟这个需求的:当用户注册完毕后,提示用户进入邮箱查看注册结果。用户打开邮箱后,可以查看到注册结果。- 异步Servlet
@WebServlet(value="/register", asyncSupported=true) public class RegisterServlet extends HttpServlet { private static final long serialVersionUID = 1L; public RegisterServlet() { super(); } protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { PrintWriter writer = response.getWriter(); writer.println("main thread start!"); // 获取异步上下文对象 AsyncContext async = request.startAsync(); // 设置超时 async.setTimeout(2000); // 开启异步上下文对象 async.start(new ComputeThread(async)); writer.println("main thread end!"); writer.println("please check your email"); } @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { this.doPost(req, resp); } } - 异步线程
public class ComputeThread implements Runnable{ private AsyncContext async; public ComputeThread(AsyncContext async) { super(); this.async = async; } @Override public void run() { HttpServletRequest request = (HttpServletRequest) async.getRequest(); HttpSession session = request.getSession(); session.setAttribute("test", "test"); // 开始耗时运算 int sum = 0; try { for(int i=0; i<10; i++) { System.out.println(i); sum = sum + i; Thread.sleep(1000); } // 对运算结果进行分析 String message = "sorry, your register is fail"; if(sum == 45) { message = "bingo!"; } session.setAttribute("message", message); } catch (InterruptedException e) { e.printStackTrace(); } } }
-
JavaWeb-过滤器
过滤器
Filter是Servlet规范的三大组件之一。顾名思义,就是过滤。可以在请求到达目标资源 之前先对请求进行拦截过滤,即对请求进行一些处理;也可以在响应到达客户端之前先对响应进行拦截过滤,即对响应进行一些处理。
Filter生命周期
Filter的生命周期与Servlet的生命周期类似,其主要生命周期阶段有四个:Filter对象的创建、Filter 对象的初始化、Filter执行doFilter()方法,及最终 Filter对象被销毁。Filter的整个生命周期过程的执行,均由 Web服务器负责管理。即 Filter 从创建到销毁的整个过程中方法的调用,都是由 Web 服务器负责调用执行,程序员无法控制其执行流程。

Filter的特征
- Filter是单例多线程的。
- Filter是在应用被加载时创建并初始化,这与 Servlet不同的地方。Servlet是在该Servlet被第一次访问时创建。Filter与Servlet的共同点是,其无参构造器与 init()方法只会执行一次。
- 用户每提交一次该Filter可以过滤的请求,服务器就会执行一次doFilter()方法,即doFilter()方法是可以被多次执行的。
- 当应用被停止时执行destroy()方法,Filter被销毁,即 destroy()方法只会执行一次。
- 由于Filter是单例多线程的,所以为了保证线程安全性,一般情况下是不为Filter类定义可修改的成员变量的。因为每个线程均可修改这个成员变量,会出现线程安全问题。
FilterConfig
与 ServletConfig类似,FilterConfig指的是当前 Filter在
web.xml中的配置信息。同样是一个Filter对象一个FilterConfig对象,多个Filter对象会有多个FilterConfig 对象。 在Web容器调用init()方法时,Web容器首先会将web.xml中当前Filter类的配置信息封装为一个FilterConfig对象。Web容器会将这个对象传递给init()方法中的FilterConfig参数。也就是说,我们要获取FilterConfig对象,就需要像 Servlet获取ServletConfig一样,在Filter类中声明一个FilterConfig成员变量,并在init()方法中赋值。Filter的执行过程
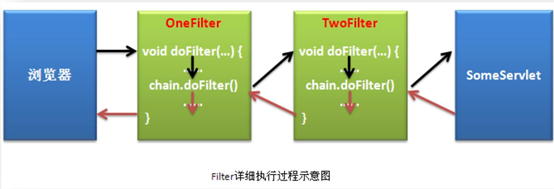
Servlet的执行原理分析:
两个Map:Web容器存在两个Map,他们的key都是
url-pattern的值,第一个map的value为Servlet对象的引用,第二个map的value为<servlet-class>的值。 执行过程: 当Servlet请求到达Servlet容器时,先对请求进行解析,解析出的URI作为比较对象,从第一个map中查找是否有相同的key,如果有,则读取value,执行该servlet的service()方法。 如果在第一个map中没找到,则在第二个map中找,读取到<servlet-class>的值,然后利用反射机制创建servlet实例,并将该实例的引用放入第一个map中,然后执行service()方法。 若第二个map中也没找到则404.Filter的执行原理分析:
一个Map
像存放Servlet信息的两个Map一样,在服务器中同样存在用于存放Filter相关信息的Map。只不过Map只有一个,而非两个。这个Map的
key是Filter的<url-pattern/>。当然,若Filter没有设置<url-pattern/>而是使用了<servlet-name/>,则会将指的Servlet的<url-pattern/>值放到Map中作为key。Map的value为该Filter的引用.在应用被启动时,服务器会自动将所有的Filter实例创建,并将它们的引用放入到相应Map的value中。一个数组
在服务器中,对于每一个请求,还存在着一个数组,用于存放满足当前请求的所有Filter及最终的目标资源。 当请求到达服务器后,服务器会解析出URI,然后会先从Filter的Map中查找所有与该请求匹配的Filter,每找到一个就将其引用存放到数组中,后继承查找。直到将所有匹配的Filter全部找到并添加到数组中。这个数组就是对于当前请求所要进行处理的一个“链”,包含多个Filter。服务器将按照这个“链”的顺序对请求进行依次过滤处理。 注意,我们发现对于Filter的Map的查询过程与对于Servlet的Map的查询过程是不同的。对于Servlet的Map的查询过程是,只要找到一个匹配的key,则将不再向后查找。而对于Filter的Map的查找,则是遍历所有key,将所有匹配的元素都查找出来。
ApplicationFilterChain部分源码解读
public final class ApplicationFilterChain implements FilterChain { public static final int INCREMENT = 10; /** * Filters. */ private ApplicationFilterConfig[] filters = new ApplicationFilterConfig[0]; /** * The int which is used to maintain the current position * in the filter chain. */ private int pos = 0; /** * The int which gives the current number of filters in the chain. */ private int n = 0; /** * The servlet instance to be executed by this chain. */ private Servlet servlet = null; void addFilter(ApplicationFilterConfig filterConfig) { // Prevent the same filter being added multiple times for(ApplicationFilterConfig filter:filters) if(filter==filterConfig) return; if (n == filters.length) { ApplicationFilterConfig[] newFilters = new ApplicationFilterConfig[n + INCREMENT]; System.arraycopy(filters, 0, newFilters, 0, n); filters = newFilters; } filters[n++] = filterConfig; } public void doFilter(ServletRequest request, ServletResponse response) throws IOException, ServletException { ... } }装饰者设计模式
Decorator Pattern,能够在不修改目标类也不继承的情况下,动态地扩展一个类的功能。它是通过创建一个
包装对象,也就是装饰者来达到增强目标类的目的的。两个要求:
- 装饰者类与目标类要实现相同的接口,或继承自相同的抽象类。
- 装饰者类中要有目标类的引用作为成员变量,而具体的赋值一般通过带参构造器完成。
这两个要求的目的是,在装饰者类中的方法可以调用目标类的方法,以增强这个方法。而增强的这个方法是通过
重写的方式进行的增强,所以要求实现相同的接口或继承相同的抽象类。
具体步骤:
- 定义业务接口 ISomeService
// 业务逻辑接口 public interface ISomeService { // 目标方法 String doSome(); } - 定义目标类 SomeServiceImpl
// 目标类 public class SomeServiceImpl implements ISomeService{ @Override public String doSome() { return "minmin"; } } - 定义装饰者基类 SomeServiceWrapper
// 装饰者基类 // 要求1: 装饰者要与目标类实现相同的接口或继承相同的类 // 要求2: 装饰者要有目标类的引用 // 要求3: 要有无参构造器 // 要求4: 不对目标方法进行重写 public class SomeServiecWrapper implements ISomeService{ // 目标对象 private ISomeService target; public SomeServiecWrapper() { super(); } // 通过带参构造器传入目标对象 public SomeServiecWrapper(ISomeService target) { this.target = target; } @Override public String doSome() { // 仅调用目标类的方法 return target.doSome(); } } - 定义去空格装饰者类 TrimDecorator
public class TrimDecorator extends SomeServiecWrapper{ public TrimDecorator() { super(); } public TrimDecorator(ISomeService target) { super(target); } @Override public String doSome() { return super.doSome().trim(); } } - 定义小写变大写装饰者类ToUpperCaseDecorator
public class UpperCaseDecorator extends SomeServiecWrapper{ public UpperCaseDecorator() { super(); } public UpperCaseDecorator(ISomeService target) { super(target); } @Override public String doSome() { return super.doSome().toUpperCase(); } } - 定义测试类MyTest
public class MyTest { public static void main(String[] args) { // 创建目标对象 ISomeService target = new SomeServiceImpl(); // 创建装饰者 ISomeService service = new TrimDecorator(target); // 创建装饰者2,形成装饰着琏 ISomeService service2 = new UpperCaseDecorator(service); // 使用装饰者的业务方法 String result = service2.doSome(); System.out.println("result: " + result); } }装饰者设计模式与静态代理设计模式的对比
相同点
- 装饰者类与目标类要求实现同一接口;静态代理类与目标类要求也实现同一接口。
- 装饰者类与静态代理类都可以实现增强目标类的功能。
- 装饰者类与静态代理类中都具有目标类的引用,目的都是为了在其中调用目标类的方法。
不同点
- 装饰者设计模式就是为了增强目标类;静态代理设计模式是为了保护和隐藏目标对象,让客户类只能访问代理对象,而不能直接访问目标对象。
- 装饰者类中的目标类的引用是通过带参构造器传入的;静态代理类中的目标类的引用,一般都是在代理类中直接创建的,目的就是为了隐藏目标对象。
- 装饰者基类一般不对目标对象进行增强,而是由不同的具体装饰者进行增强的,且这些具体的装饰者可以形成增强链,对目标对象进行连续增强。静态代理类会直接对目标对象进行增强,需要哪些增强的功能,一次性在静态代理类中完成,没有增强链的概念。
-
JavaWeb-系统开发模型
开发模型
模型发展阶段
1.纯JSP
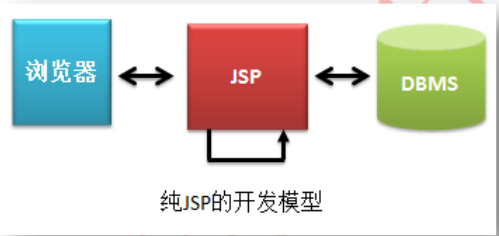 这个模型里的所有业务处理,数据显示功能都由JSP页面完成,缺点时JSP页面结构很乱,显示功能与业务功能代码没有划分,维护与升级很麻烦。
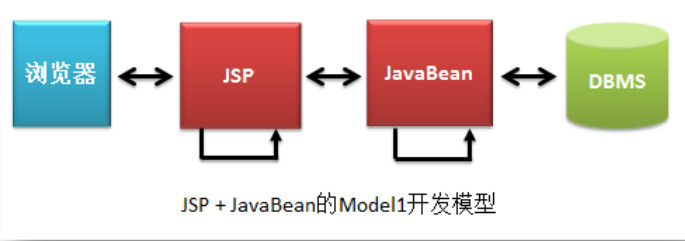
这个模型里的所有业务处理,数据显示功能都由JSP页面完成,缺点时JSP页面结构很乱,显示功能与业务功能代码没有划分,维护与升级很麻烦。2.JSP+JavaBean的Model1
 Javabean的分类:
Javabean的分类:
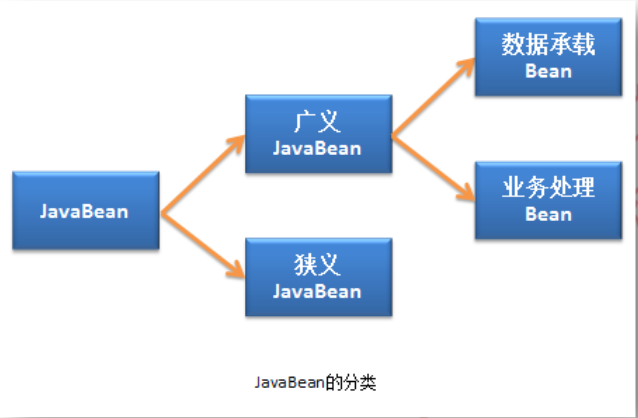 狭义的Javabean是指符合Sun公司的JavaBean规范的Java类
狭义的Javabean是指符合Sun公司的JavaBean规范的Java类
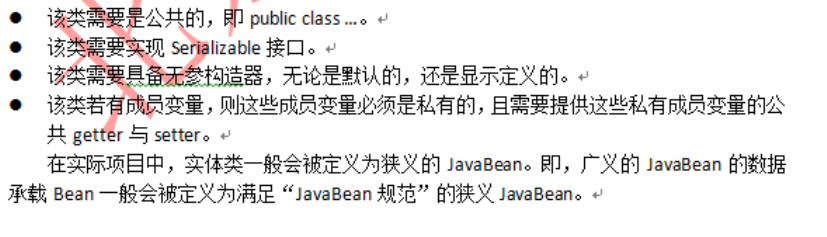
3.MVC的Model1
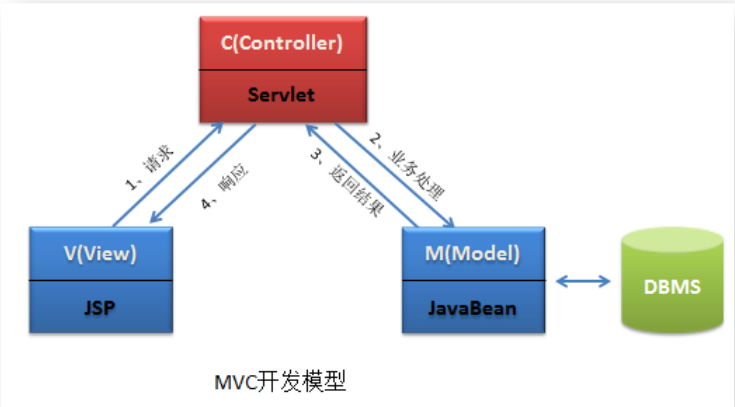
4.三层架构
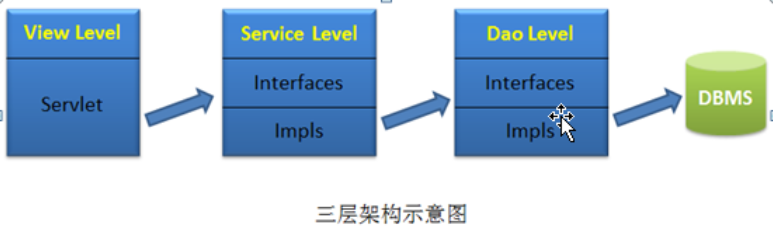
- View层:视图层,也称web层,用于接收用户提交请求的代码再这里编写
- Service层:系统的主要业务逻辑在这里完成。
- Dao层:Data Access Objet, 持久层,数据访问层,直接操作数据库的代码在这里编写。
5. MVC+三层架构
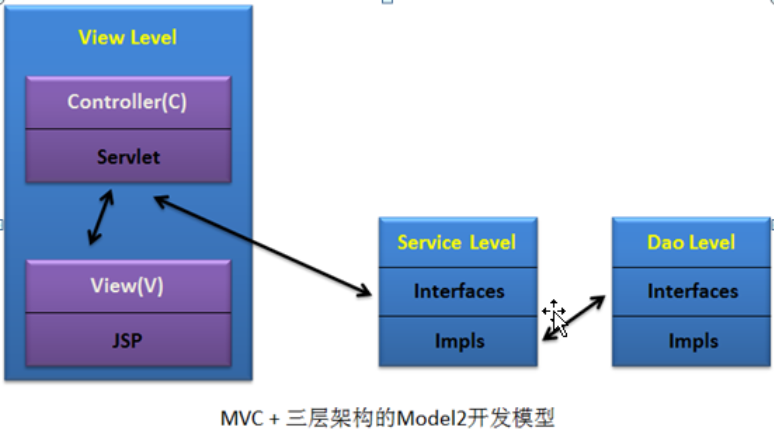 将M层分成了三层架构的Service层和Dao层
将M层分成了三层架构的Service层和Dao层
-
JavaWeb-JSP
JSP的调用与运行原理
JSP,即 JavaServerPages,是Java服务器页面。JSP 技术是在传统的静态网页HTML文件中插入Java代码片断和 JSP 标签后形成的一种文件,其后缀名为.js使用 JSP 开发的Web应用是跨平台的,既能在Linux上运行,也能在其他操作系统上运行。
JSP本质是一个servlet,每个JSP页面在第一次被访问时,WEB容器会把请求交给JSP引擎(即一个JAVA程序)处理。JSP引擎先将JSP翻译成一个
_jspServlet(实质也是一个servlet),然后编译为class文件,然后按照servlet的调用方式进行调用。- 服务器会将jsp先翻译成servlet,这个servlet位于tomcat服务器
work目录,这jsp类的父类是org.apache.jasper.runtime.HttpJspBase,这个HttpJspBase类继承自HttpServlet

- 向服务器发请求会调用servlet的
service方法;同样地,访问jsp会调用这个JSP类的_jspService方法。 - JSP中的标签语言会在
_jspService方法中通过out.write()写出来;JSP中的Java代码会原封不动的搬到_jspService方法中。 - 在_jspService方法中提前准备好了一些对象供JSP调用,如:
out,page,application,request,response等等。
java代码块:<% %>, 对应到jspservice方法中的代码 jsp声明语句块:<%! %>, 对应到jspservlet类中的代码。 jsp表达式块:<%= %> 被jsp引擎翻译到jspService()的out.write()方法中输出。
JSP核心
JSP内置对象
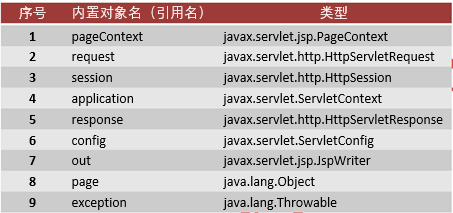
在
jspServlice()方法中内置了九个对象
JSP指令(directive)
page指令
page指令用于设置当前JSP页面的相关信息。一个 JSP 文件中可以包含多个 page 指令。
pageEncoding属性用于设置当前JSP页面所使用的字符编码格式。即,用户在浏览器中通过右击查看编码所看到的编码格式。contentType属性用于设置当前JSP页面呈现于用户浏览器中的内容类型,通常为text/html类型,即html格式的文本。 总结: 当内容类型为text/html时,使用pageEncoding属性与contentType属性效果是相同的。只有当内容类型不为text/html时,才专门使用contentType属性指定。在指定字符编码时,这两个属性一般不同时使用。errorPage属性用于指定,当前页面运行过程中发生异常时所要跳转到的页面。- 当一个页面的page指令中设置
isErrorPage的值为true时,表明当前页面为一个“错误处理页面”。默认isErrorPage的值为false。一旦一个页面page指令的isErrorPage属性被指定为了 true,在_jspService()方法中,多出了一个变量exception。这就是内置对象exception,可以在JSP的Java代码块、表达式块中直接使用的内置对象。 session属性用于指定当前页面中是否可以直接使用内置对象session。默认为true,可以看到session的创建,使用的是无参方法getSession()。若设置session属性的值为false,查看生成的Servlet代码,会发现根本就没有出现内置对象session。
include指令
被include指定包含的文件,可以是JSP动态页面文件,也可以是HTML静态页面文件。
<%@ include file=””%> JS 翻译引擎在翻译时,会将include指令所 指定的文件内容直接翻译到当前JSP对应的Servlet 中,形成一个.java文件。这就说明一个问题:这个包含操作是在编译之前完成的,是在编译之前由 JSP 翻译引擎完成的,不是在程序运行期完成的。这种包含是一种静态包含,称为静态联编。 由于在编译期就将这些文件合并为了一个 Servlet 文件,所以,整个过程就一个_jspService()方法。也就是说,这些文件之间是可以相互访问局部变量的。只要满足变量声明与使用的先后顺序即可。
JSP动作(Action)
JSP动作是指,使用系统定义好的标签来完成本应由Java代码来完成的功能。JSP动作很多,但在实际开发时常用的就两个:
转发动作与包含动作。底层使用的是RequestDispatcher的forward()与include()方法实现的。而这两份种请求转发方式的本质区别是,标准输出流的开启时间不同。forward()方式的标准输出流是在目标资源中开启的标准输出流,而include()方式的标准输出流则是在当前发出包含运作的页面中开启的。所以,forward()动作的发起页面中是无法向标准输出流中写入数据的;而include()动作的发起页面及目标页面中均可向标准输出流中写入数据。注意: 使用include动作时,work目录下会出现两个java文件,这是在运行期间完成的,是在程序运行过程中,由
index_jsp文件中的_jspService()方法通过JspRuntimeLibrary类的include()方法调用了left_jsp文件中的_jspService()方法。在运行期所执行的这种包含,称为动态联编。应用场景:
- 在静态联编与动态联编均可使用时,一般使用静态联编。因为在程序运行时只存在一个Servlet,对资源的消耗较少,且不存在调用问题,执行效率较高。
- 若在两个文件间需要共享同一变量,此时只能使用静态联编。
- 若在两个文件间存在同名变量,且不能混淆,此时只能使用动态联编。
- 服务器会将jsp先翻译成servlet,这个servlet位于tomcat服务器
-
JavaWeb-Servlet(2)
请求转发与重定向
请求转发
请求转发是指,资源1在服务器内部,直接跳转到资源2,所以请求转发也称为服务器内跳转。整个过程浏览器只发出一次请求,服务器只发出一次响应。所以,无论是资源1还是资源2,整个过程中,只存在一次请求,即用户所提交的请求。所以,无论是资源1 还是资源2,它们均可从这个请求中获取到用户提交请求时所携带的相关数据。
重定向
重定向是指,资源1需要访问资源2,但并未在服务器内直接访问,而是由服务器自动向浏览器发送一个响应,浏览器再自动提交一个新的请求,这个请求就是对资源 2 的请求。对于资源2的访问,是先跳出了服务器,跳转到了客户端浏览器,再跳回到了服务器。所以重定向又称为服务器外跳转。
重定向中中文乱码问题
因为http协议底层用的是tcp协议,tcp协议利用字节流进行传输,所以要先利用UrlEncoder对放入URL中的变量进行编码,然后接受以后利用UrlDecode进行解码
// 解决重定向中URL乱码问题 String encodeUsername = URLEncoder.encode(username, "UTF-8"); // redirect response.sendRedirect("second?user=" + encodeUsername); String user = request.getParameter("user"); // 解码 user = URLDecoder.decode(user, "UTF-8");Servlet 的线程安全问题
JVM 中可能存在线程安全问题的数据分析
栈内存数据分析
栈内存是多例的,即JVM会为每个线程创建一个栈,所以其中的数据不是共享的。另外,方法中的局部变量存放在Stack的栈帧中,方法执行完毕,栈帧弹栈,局部变量消失。局部变量是局部的,不是共享的。所以栈内存中的数据不存在线程安全问题。
堆内存数据分析
一个 JVM 中只存在一个堆内存,堆内存是共享。被创建出的对象是存放在堆内存的,而存放在堆内存中的对象,实际就是对象成员变量的值的集合。即成员变量是存放在堆内存的。堆内存中的数据是多线程共享的,也就是说,堆内存中的数据是存在线程安全问题的。
方法区数据分析
一个 JVM 中只存在一个方法区。静态变量与常量存放在方法区,方法区是多线程共享的。常量是不能被修改的量,所以常量不存在线程安全问题。静态变量是多线程共享的,所以静态变量存在线程安全问题。
解决方法: 1.避免使用成员变量 2.若使用成员变量,可以使用synchronized方法进行串行化cao