Welcome to Andy's Blog!
一念净心,花开遍世界-
ARTS_Week5
Algorithm
leetcode28:Implement strStr()
Description
Implement strStr()
Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example
Input: haystack = “hello”, needle = “ll” Output: 2
Input: haystack = “aaaaa”, needle = “bba” Output: -1
Clarification
What should we return when needle is an empty string? This is a great question to ask during an interview.
For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C’s strstr() and Java’s indexOf().
Solution
Approach1: brute force
We can set two points, one points to the start of haystack, the other points ot the start of needle, and use two loops to iterate the whole cases.
class Solution { public int strStr(String haystack, String needle) { if(needle.length() == 0) return 0; int i = 0; int j = 0; while(i < haystack.length() && j < needle.length()) { if(haystack.charAt(i) == needle.charAt(j)) { i++; j++; } else { i = i - j + 1; j = 0; } } if(j == needle.length()) { return i - j; } else { return -1; } } }Runtime: 4 ms, faster than 47.77% of Java online submissions for Implement strStr(). Memory Usage: 38.8 MB, less than 7.14% of Java online submissions for Implement strStr().
class Solution { public int strStr(String haystack, String needle) { if(needle.length() == 0) return 0; int n = haystack.length(); int m = needle.length(); for(int i = 0; i <= n - m; i++) { int j = 0; for(; j < m; j++) { if(needle.charAt(j) != haystack.charAt(i + j)) { break; } } if(j == m) return i; } return -1; } }Runtime: 1 ms, faster than 88.44% of Java online submissions for Implement strStr(). Memory Usage: 37.4 MB, less than 81.73% of Java online submissions for Implement strStr().
Complexity analysis
Time complextiy : O((n-m+1)*m). Assume that n is the length of haystack, and m is the length of needle.
Space complexity : O(1).
Approach2: KMP Algorithm
KMP is a classic algorithm, there are many useful resources in the Internet, I will list below. KMP Substring Searching KMP by Python
class Solution { public int strStr(String haystack, String needle) { if(needle.length() == 0) return 0; int n = haystack.length(); int m = needle.length(); int i = 0; int j = 0; int[] lps = new int[m]; computeLPSArray(needle, lps); while(i < n && j < m ) { if(needle.charAt(j) == haystack.charAt(i)) { i++; j++; } else { if(j != 0) { j = lps[j-1]; } else { i++; } } } if(j == m) { return i - j; } else { return -1; } } public void computeLPSArray(String needle, int[] lps) { int len = 0; int i = 1; lps[0] = 0; int m = needle.length(); while(i < m) { if(needle.charAt(i) == needle.charAt(len)) { lps[i++] = ++len; } else { if(len != 0) { len = lps[len - 1]; } else { lps[i] = 0; i++; } } } } }Complexity analysis
Time complextiy : O(n + m). Assume that n is the length of haystack, and m is the length of needle.
Space complexity : O(m).
Runtime: 3 ms, faster than 68.76% of Java online submissions for Implement strStr(). Memory Usage: 37.3 MB, less than 86.86% of Java online submissions for Implement strStr().
Review
This week, I read the Netfix technology blog on the medium, named Why is Python so slow?
The author gives three top theories
- It’s the GIL (Global Interpreter Lock)
- It’s because its interpreted and not compiled
- It’s because its a dynamically typed language
It’s the GIL
In multi-thread programming, Unlike a single-threaded process, you need to ensure that when changing variables in memory, multiple threads don’t try and access/change the same memory address at the same time.
When CPython creates variables, it allocates the memory and then counts how many references to that variable exist,If the number of references is 0, then it frees that piece of memory from the system. This is why creating a “temporary” variable within say, the scope of a for loop, doesn’t blow up the memory consumption of your application.
The challenge then becomes when variables are shared within multiple threads, how CPython locks the reference count. There is a “global interpreter lock” that carefully controls thread execution. The interpreter can only execute one operation at a time, regardless of how many threads it has.
If you have a web-application (e.g. Django) and you’re using WSGI, then each request to your web-app is a separate Python interpreter, so there is only 1 lock per request.
It’s because its an interpreted language
If at a terminal you wrote python myscript.py then CPython would start a long sequence of reading, lexing, parsing, compiling, interpreting and executing that code.
So, why is Python so much slower than both Java and C# in the benchmarks if they all use a virtual machine and some sort of Bytecode? Firstly, .NET and Java are JIT-Compiled.
It’s because its a dynamically typed language
In a “Statically-Typed” language, you have to specify the type of a variable when it is declared. Those would include C, C++, Java, C#, Go.
In a dynamically-typed language, there are still the concept of types, but the type of a variable is dynamic.
Conclusion
Python is primarily slow because of its dynamic nature and versatility. It can be used as a tool for all sorts of problems, where more optimised and faster alternatives are probably available.
Tips
This week, I will share a chrome extension named word discoverer, it has following three main functions:
- highlight the uncommon words and expressions
- translate the word you choose on the website, and you can define the source translate website.
- save the vocabulary you added
Enjoy your time.
Share
This week I will share the concept of the local and global variable by python.
In brief, Parameters and variables that are assigned in a called function are said to exist in that function’s local scope. Variables that are assigned outside all functions are said to exist in the global scope.
Scopes matter for several reasons:
- Code in the global scope cannot use any local variables.
- However, a local scope can access global variables.
- Code in a function’s local scope cannot use variables in any other local scope.
- You can use the same name for different variables if they are in different scopes. That is, there can be a local variable named spam and a global variable also named spam.
I will use the classic examples in the book to explain them.
Local Variables Cannot Be Used in the Global Scope
def spam(): eggs = 31337 spam() print(eggs) # NameError: name 'eggs' is not definedThis makes sense if you think about it; when the program execution is in the global scope, no local scopes exist, so there can’t be any local variables. This is why only global variables can be used in the global scope.
Local Scopes Cannot Use Variables in Other Local Scopes
def spam(): eggs = 99 bacon() print(eggs) def bacon(): ham = 101 eggs = 0 pam()Global Variables Can Be Read from a Local Scope
def spam(): print(eggs) eggs = 42 spam() print(eggs)Since there is no parameter named eggs or any code that assigns eggs a value in the spam() function, when eggs is used in spam(), Python considers it a reference to the global variable eggs.
Local and Global Variables with the Same Name
def spam(): eggs = 'spam local' print(eggs) # prints 'spam local' def bacon(): eggs = 'bacon local' print(eggs) # prints 'bacon local' spam() print(eggs) # prints 'bacon local' ggs = 'global' bacon() print(eggs) # prints 'global'Since these three separate variables all have the same name, it can be confusing to keep track of which one is being used at any given time. This is why you should avoid using the same variable name in different scopes.
The global Statement
def spam(): global eggs eggs = 'spam' # this is the global def bacon(): eggs = 'bacon' # this is a local def ham(): print(eggs) # this is the global eggs = 42 # this is the global spam() print(eggs)If you ever want to modify the value stored in a global variable from in a function, you must use a global statement on that variable.
If you try to use a local variable in a function before you assign a value to it, as in the following program, Python will give you an error.
def spam(): print(eggs) # ERROR! UnboundLocalError: local variable 'eggs' referenced before assignment eggs = 'spam local' eggs = 'global' spam()This error happens because Python sees that there is an assignment statement for eggs in the spam() function and therefore considers eggs to be local. But because print(eggs) is executed before eggs is assigned anything, the local variable eggs doesn’t exist. Python will not fall back to using the global eggs variable.
Reference
-
ARTS_Week4
From week4, I will write this kind if blog in English, hope everyone enjoy it and we can discuss with everything.
Algorithm
leetcode27:Remove Element
Description
Given an array nums and a value val, remove all instances of that value in-place and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
The order of elements can be changed. It doesn’t matter what you leave beyond the new length.
Example
Given nums = [3,2,2,3], val = 3, Your function should return length = 2, with the first two elements of nums being 2. It doesn’t matter what you leave beyond the returned length.
Given nums = [0,1,2,2,3,0,4,2], val = 2, Your function should return length = 5, with the first five elements of nums containing 0, 1, 3, 0, and 4. Note that the order of those five elements can be arbitrary. It doesn’t matter what values are set beyond the returned length.
Solution
Approach: Two points If we got the key concept of two points, we can solve this problem very quickly, this is very same as the leetcode26.
In this case, we have to solve the problem in place, it means we can not use another array, beacuse it is impossible to remove en element from the array without making a copy of the array, so we can use two points. One is slow point i, it’s duty is to record the elemnet that we want. The other is fast point j, it’s duty is to scan all the element in the array.
class Solution { public int removeElement(int[] nums, int val) { if(nums == null || nums.length == 0) return 0; int i = 0; for(int j = 0; j < nums.length; j++) { if ( nums[j] != val ) { nums[i] = nums[j]; i++; } } return i; } }Complexity analysis
Time complexity : O(n). Assume the array has a total of n elements, both i and j traverse at most 2n steps.
Space complexity : O(1).
Another way:
Now consider case where the array contains less elements to remove, we will do many unnecessary copy operation.
So we can use while loop, because it is an unsure time loop, if nums[i] == val, we can swap the current element with the last one, and then dispose the last element, which means the lenght, we can just use one point.
class Solution { public int removeElement(int[] nums, int val) { if(nums == null || nums.length == 0) return 0; int n = nums.length; int i = 0; while(i < n) { if(nums[i] == val) { nums[i] = nums[n-1]; n--; } else { i++; } } return n; } }Time complexity : O(n). Assume the array has a total of n elements, i will traverse at most n steps.
Space complexity : O(1).
Review
I have read and look through several materials these evening, just to find a topic and learn it to write the review. Up to now, I will do a reivew on the topic of how to work in Google. These are the main reference for the review.
Google is a great company, I think it’s most people’s dream company, I will share some my own opinion about how to get the google offer.
First of all, we have to be confident about ourselves, we can not be afraid of it in our mind and think is just a tall mountain that we can not conquer.
Ok, let us talk about some concrete methods and steps.
First, we have to find the right position, we can find the information in linkedin and google career, for me, my position is software engineer.
Second, we have to create a list of skills, we can find the “minimum qualifications” and “preferred qualification”, with that, we can see our strenghts and shorts, and the most important and difficult task is to make a proper learning plan and stick to it! I am planning to write a blog to share how to make a plan and execuate it efficiently.
Thirdly, network with the current google employees. This is important, however, few people have the connection with googler, it looks like a little bit hard. But I always believe that where there is a will, there is a way.
For example, we can linkedin and hicounselor, both are the efficient applications to help people build a connection with the googler. Also, it is a good way to apply with employee referral, there are more than 75% hiring are done through internal referral.
Finally, strategy to ace the interview, there are three most important things to be done:
- You have thoroughly studied basic and advanced concepts of skills identified in step 2
- You have identified key insights of job position from company insiders
- You have built good relationship with current employees of Google and Facebook so that they can endorse you. THIS IS THE MOST IMPORTANT
Trust yourself and take interview with full confidence, show your passion and zeal to learn during the interview. If you can convince the interviewer that you are willing to learn and improve your skills with time, then you will definitely be the winner.
Tip
This week I spent most time to find some tools to make my work and study efficiently, this time, I want to share an application named Trello, it has mobile application and online website, we can use it make todo list and make some card.
Next week, I just want to share some useful code skills, because this section is responsible for the code skill, I think.
Share
I am happy to share my CS knowledge and work interview learning plan, I will share the online resource and my daily study plan.
I am always confused about how to find the best and most suitable learning reosurce for myself, honestly, there are huge resource in the Internet, and I am very appreaciative for the inventor of world wide website – Tim Berners-Lee, I have upload the video about him to the BiliBili and other pioneers of the CS industry, thanks for the contribution for the whole human. However, until now, I just have not made a practical plan to execuate it step by step.
So, I create a github project to record my cs notes and somoe resources which I thought vaulable, and I will record my study plan on it, hope you can join us and work together.
-
Introduction_to_Computation-MIT6_0001F16_Lec8
第八节课,这节主要讲python里class的概念,接下来摘抄部分slide。
OBJECT ORIENTED PROGRAMMING
EVERYTHING IN PYTHON IS AN OBJECT (and has a type)
- can create new objects of some type
- can manipulate objects
- can destroy objects
- explicitly using del or just “forget” about them
- python system will reclaim destroyed or inaccessible objects – called “garbage collection”
ADVANTAGES OF OOP
- bundle data into packages together with procedures that work on them through well-defined interfaces
- divide-and-conquer development
- implement and test behavior of each class separately
- increased modularity reduces complexity
- classes make it easy to reuse code
- many Python modules define new classes
- each class has a separate environment (no collision on function names)
- inheritance allows subclasses to redefine or extend a selected subset of a superclass’ behavior
THE POWER OF OOP
- bundle together objects that share
- common attributes and
- procedures that operate on those attributes
- use abstraction to make a distinction between how to implement an object vs how to use the object
- build layers of object abstractions that inherit behaviors from other classes of objects
- create our own classes of objects on top of Python’s basic classes
-
Introduction_to_Computation-MIT6_0001F16_Lec7
第七节课,坚持坚持坚持,入门课一定要看完,笔记也一定要写完,不论知识多么简单,都要写下来,因为这是对我自己的约定,一定要完成。
#TESTING, DEBUGGING, EXCEPTIONS, ASSERTIONS
SET YOURSELF UP FOR EASY TESTING AND DEBUGGING
- from the start, design code to ease this part break program up into modules that can be tested and debugged individually
- document constraints on modules • what do you expect the input to be? • what do you expect the output to be?
- document assumptions behind code design
CLASSES OF TESTS
- Unit testing
- validate each piece of program
- testing each function separately
- Regression testing
- add test for bugs as you find them
- catch reintroduced errors that were previously fixed
- Integration testing
- does overall program work? • tend to rush to do this
DEBUGGING STEPS
- study program code
- don’t ask what is wrong
- ask how did I get the unexpected result • is it part of a family?
- scientific method
- study available data
- form hypothesis
- repeatable experiments
- pick simplest input to test with
example code:
def get_ratios(L1, L2): """ Assumes: L1 and L2 are lists of equal length of numbers Returns: a list containing L1[i]/L2[i] """ ratios = [] for index in range(len(L1)): try: ratios.append(L1[index]/L2[index]) except ZeroDivisionError: ratios.append(float('nan')) #nan = not a number except: except: raise ValueError('get_ratios called with bad arg') return ratiosAssertions
- want to be sure that assumptions on state of computation are as expected
- use an assert statement to raise an AssertionError exception if assumptions not met
- an example of good defensive programming
ASSERTIONS AS DEFENSIVE PROGRAMMING:
- assertions don’t allow a programmer to control response to unexpected conditions
- ensure that execution halts whenever an expected condition is not met
- typically used to check inputs to functions, but can be used anywhere
- can be used to check outputs of a function to avoid propagating bad values
- can make it easier to locate a source of a bug.
WHERE TO USE ASSERTIONS?
- goal is to spot bugs as soon as introduced and make clear where they happened
- use as a supplement to testing
- raise exceptions if users supplies bad data input
- use assertions to
- check types of arguments or values
- check that invariants on data structures are met • check constraints on return values
- check for violations of constraints on procedure (e.g. no duplicates in a list)
-
ARTS_Week3
Algorithm
leetcode26:Remove Duplicates from Sorted Array
Description
Given a sorted array nums, remove the duplicates in-place such that each element appear only once and return the new length.
Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.
Example
Given nums = [1,1,2], Your function should return length = 2, with the first two elements of nums being 1 and 2 respectively. It doesn’t matter what you leave beyond the returned length.
Given nums = [0,0,1,1,1,2,2,3,3,4], Your function should return length = 5, with the first five elements of nums being modified to 0, 1, 2, 3, and 4 respectively. It doesn’t matter what values are set beyond the returned length.
Solution
Approach: Two points 首先我们得到的数组是有序的,这是前提,此时我们就可以使用双指针的方法。 开始的时候让满指针i指向0位置,慢指针j指向1位置,比较nums[i]和nums[j]。 1.如果两者相等,那么j++,i保持原来位置,这样可以过滤掉相同的内容。 2.如果两者不等,那么i++,然后nums[i]=nums[j],然后j++,开始进行上一步操作。
class Solution { public int removeDuplicates(int[] nums) { if (nums.length == 0) return 0; int i = 0; int j; for(j = 1; j < nums.length; j++) { if (nums[j] != nums[i]) { i++; nums[i] = nums[j]; } } return i+1; } }Complexity analysis
Time complextiy : O(n). Assume that n is the length of array. Each of ii and jj traverses at most nn steps.
Space complexity : O(1).
Runtime: 1 ms, faster than 99.98% of Java online submissions for Remove Duplicates from Sorted Array. Memory Usage: 40.9 MB, less than 83.62% of Java online submissions for Remove Duplicates from Sorted Array.
Review
这周要分享的还是The key to accelerating your coding skills,这篇博文也是之前陈皓叔在他博客中提到过的,现在分享一下我的感想。
文中提出了inflection point这一个观点,指出在编程学习过程中,程序员会遇到inflection point这么一个时期,在这个时期会感觉编程时所有的感觉都发生了变化,会感到自己处在黑暗中,很多技术都没学通,这一段时间会比较难熬,但是当熬过这段时间就会进入另一个境界,会得到一定的提升。
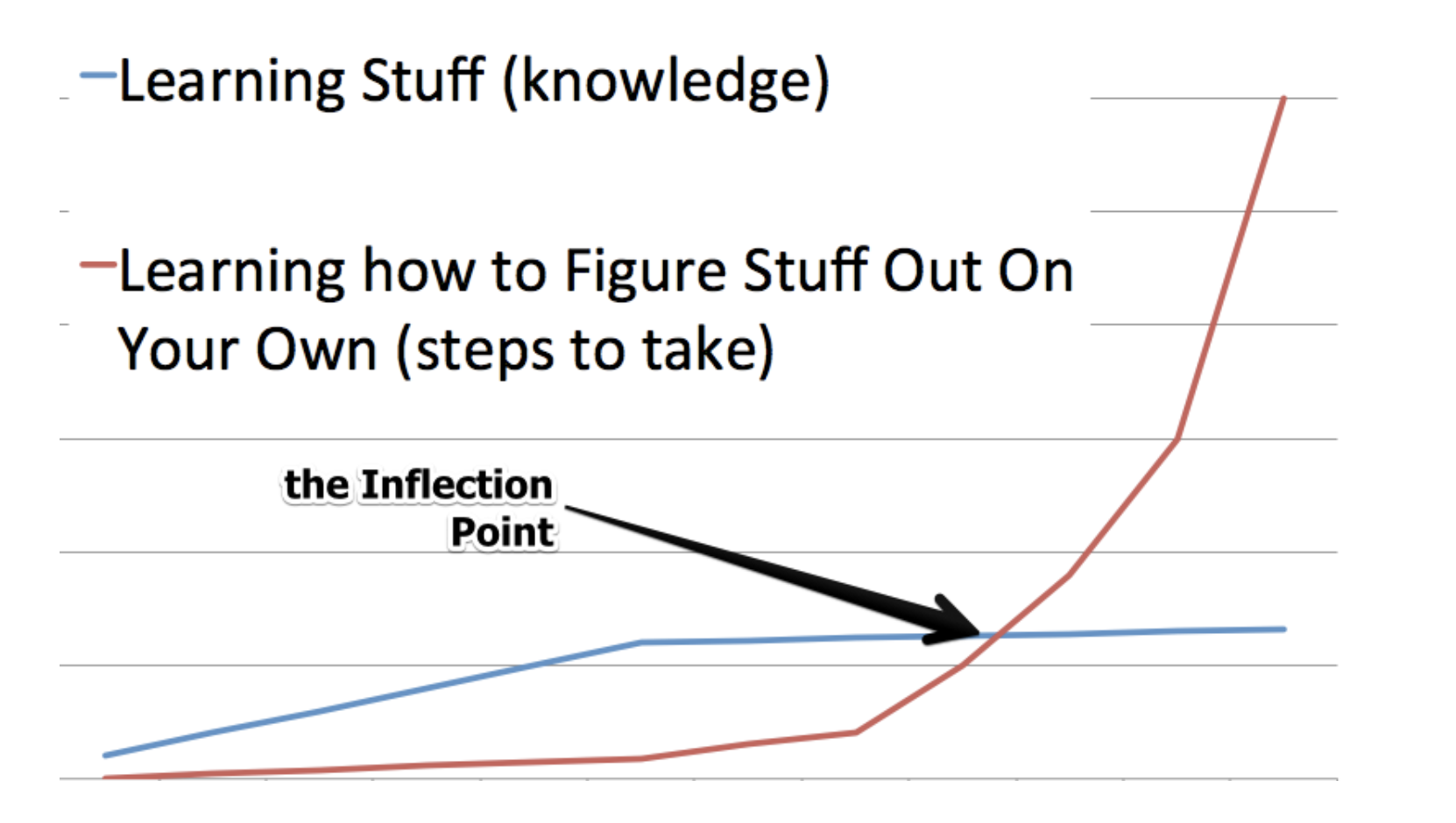
文中具体介绍了学习编程各个时期。 1.The Tutorial Phase (3-8 weeks of serious coding) 这一时期主要是学习编程的一些基础知识,如何写一些简单的程序,在这个阶段最重要的是要注意编程过程中的细节,并且学会debug,学会如何利用google解决基本的问题。
2.The Inflection Point (2-4 weeks with the right mentality) 在这一时期可能编程的速度会比平时慢很多,也会对自己产生自我怀疑,但是坚持下去,过了这段时间就会提高自己的编程水平,并且可以增加自己的自信心。
根据我的理解,度过了第二个时期,可以成为初级程序员,文中作者也指出了如果是web开发者,那么度过了inflection point,应该具备一下的基本素质: The web development inflection point:可以自己独立开发一整套web系统,包括搭建后台,设计数据库,进行数据库和前后台的连接,并可以添加第三方库。 The algorithm and data structures inflection point: 可以写出基本的排序算法,可以逆转列表,可以允许栈,堆,二叉树等数据机构进行编程,可以用递归 算法进行方案的实施。
Tips
本周分享一个学习python时比较实用的可视化网站 这里以Fibonacci的递归算法进行演示,代码如下。
def fib(x): """assumes x an int >= 0 returns Fibonacci of x""" if x == 0 or x == 1: return 1 else: return fib(x-1) + fib(x-2) fib(4)网站截图如下
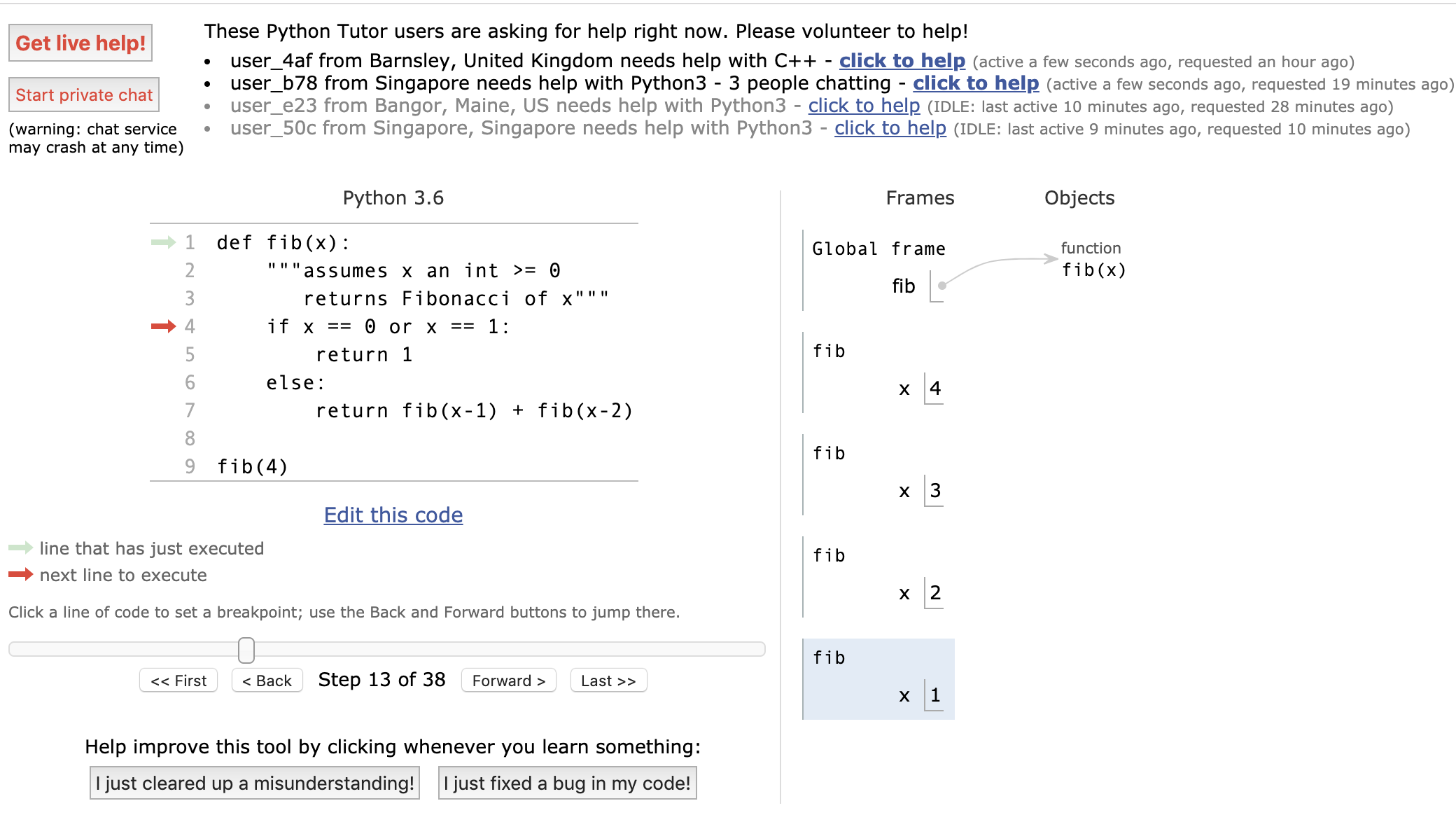
可以看到这个网站可以显示在递归的调用过程中栈和变量的变化,对于初学者来说还是很友好的,界面简洁易懂,而且还可以和这个网站在线的世界各地的程序员相互交流,相信这对于激发学习兴趣也是很有裨益的。
Share
这里分享一下自己关于递归的理解,相信学习递归的过程中大家对于递归算法会有一些理解上的困难,我自己在学的时候经常陷入了想要追踪整个递归过程的牛角尖,现在看来这对初学递归算法是非常不可取的,学习递归重要的是要先整体全局上理解其思想,然后才是去看一些细节。
具体内容首发在博客上,阅读原文
-
设计模式-设计模式入门
之前有写过设计模式的笔记,但是不够体系化,实习期间正好在看《HeadFirst设计模式》这本书,重新较系统地做一下设计模式的笔记。
欢迎来到设计模式世界
引入:模拟鸭子应用
模拟鸭子应用设计鸭子超类superclass,只包括了quack(), swim()公用的方法以及display()让子类复写的方法,此时经理提出需求要给鸭子增加fly()的功能。
###引入方法一: 在鸭子超类superclass中增加让子类继承的fly()方法。 不足: 有些鸭子子类不需要fly()方法,而且有些子类没有quack()方法,此时需要复写子类fly(),quack()方法,当这种子类较多时改动比较麻烦。
###引入方法二: 将quack(),fly()单独抽出来作为接口,让有这个功能的子类实现这些接口。 不足: 接口不具有实现代码,所以继承接口无法复用代码,当有fly与quack方法的子类较多时,需要让每个子类都实现这些接口,代码复用率低。
设计原则一:
把会变化的部分取出并“封装”起来,好让其他部分不受影响。 换句话说:如果每次新的需求一来,都会是代码发生变化,那么这部分代码就需要被抽出来,和其他稳定的代码进行区分。
所有的设计模式都提供了一套方法让系统中某部分的改变不会影响其他部分。
现在将fly(),quack()这两个方法各自单独抽出成为一个类,原来的鸭子类还是超类。
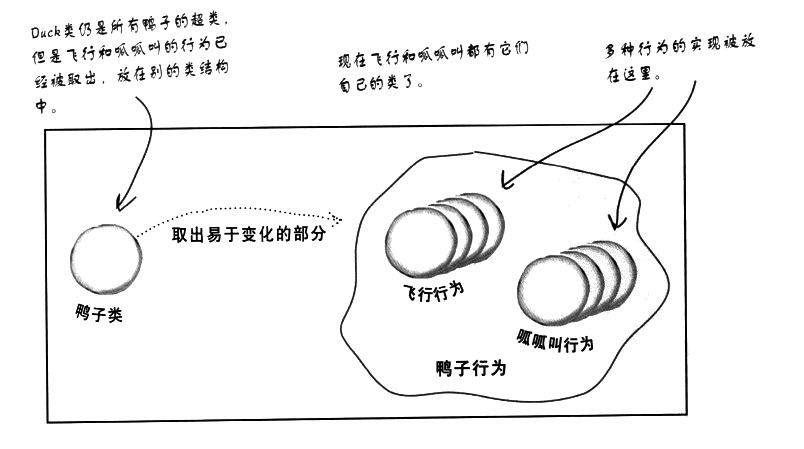
###设计原则二: 针对接口编程,而不是针对实现编程 针对接口编程其实指的是针对超类型supertype编程,在我的理解中也就是在设计时进行抽象,面向接口编程还可以使用多态的特性。
回到我们的例子中,现在设计了两个新的接口:FlyBehavior,QuackBehavior,然后分别提供他们的不同实现类。
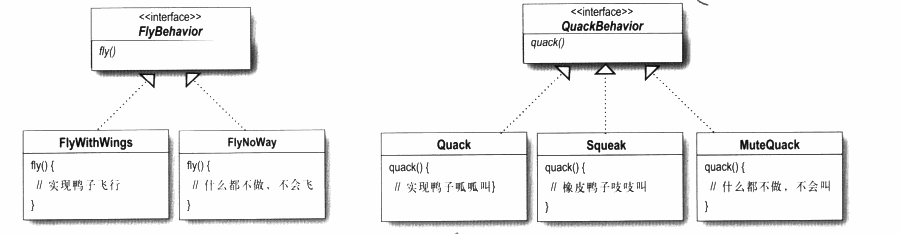
这样的设计好处在于,可以让fly和quack这两个功能被其他新建的子类服用,因为这两个功能已经和鸭子类无关了,是需要写一次实现代码即可,另一个好处是,即使新增加一些接口的实现类,也不会对已有的对象产生影响。